Case
How AI triage and RAG accelerate regulatory intake with explainable and auditable outputs

Published
3 March 2026
The problem
The weight of regulatory intake
Regulated industries live by their compliance functions. In life sciences, this partly means absorbing a constant stream of regulatory changes, guidance documents, requirements, and other updates from authorities around the world.
For a global company serving a global market, the burden is large. Each change and update needs to be identified, analysed, and evaluated. Then, if deemed relevant, the real work starts. Comparing against and updating documentation, modifying processes, and ensuring operations reflect the new requirements.
It is a crucial process for compliance, and essential work, but the sheer volume and workload make it difficult to keep pace and come out on top. In addition, higher workload and a pressured environment can often lead to human error which is far from optimal when working with regulations.
Managing data effectively within an organisation, both structured (e.g., numbers) unstructured (e.g., text) data, holds enormous potential. In this article, we will describe two essential concepts:
- Filtering through triage
- Comparison through retrieval augmented generation (RAG)
The solution
One way to approach unstructured data, especially in text form, is through the use of large language models (LLMs) and generative AI. These technologies can read, review, compare, diagnose, and even write within their trained context, acting as a subject matter expert within the business. In a well-designed solution, several specialised components can work together to create a solution that automates and improves business processes.
The main process in this case example can be divided into two parts, each requiring a unique set of solutions, with a human in the loop for testing, review, and approval.
- Filtering relevant regulatory updates, and
- Comparing the updates to the existing document repository using retrieval-augmented generation (RAG)
Together, these two components reduce noise and turn relevant regulatory events into actionable drafts for review and approval.
The first problem was triage. Not every regulatory update applies. But determining relevance requires a qualified understanding of the company, its operations, where it operates, and what is already covered by existing documentation – a very time-consuming process requiring subject matter expertise. To reduce the effort spent on this part of the process, a ‘regulatory shield’ was developed.
The regulatory shield consists of a series of lenses that represent different perspectives of the company’s operations. For example, a geography lens checks whether the regulatory change applies to markets where the company operates, while a process lens maps the topic to areas like downstream manufacturing, CAPA, or deviation management. The result is a classifier with traceability showing why something is deemed relevant.
This matters for two reasons. First, in a compliance context, “the algorithm said so” simply is not an acceptable stance. Decisions need to be explainable and auditable. Second, the business changes: new sites open and product lines expand. A traditional machine-learning classifier would need retraining. The regulatory shield just needs its lens definitions and prompts to be updated in plain language.
Performance was strong: Out of more than 1,500 historical data points, the solution achieved a 100% recall, with no false negatives (i.e., results that incorrectly indicate a lack of correlation between a regulatory update and its relevance to the company) observed in testing. In regulatory compliance, false negatives are catastrophic, a missed requirement means non-compliance. The system was designed to prioritise recall with this asymmetry in mind.
The result: 42% of the analysed incoming events were filtered out as irrelevant, representing a direct reduction in manual assessment for this process step. Instead of working through an undifferentiated pile, the team was now able to begin with a pre-sorted queue.
But filtering is only half the problem. Relevant updates still need to be translated into process and documentation changes. In this client case, we tested an initial RAG-based approach, but it was not production-ready at the time.
Through a sophisticated similarity analysis, the RAG system queries the document repository (a predefined database) using embeddings and metadata. For each regulatory update, it retrieves a shortlist of potentially impacted candidate documents and highlights the specific sections most likely to require changes.
These candidates and the relevant sections within the candidates are then reviewed by specialised agents with predefined roles: one agent to analyse the relationship, one agent to write and draft a suggested update, and one agent to review and evaluate whether the draft correctly addresses the regulatory requirement.
This RAG approach automates parts of the workflow while preserving traceability, because each draft change is linked back to the retrieved regulatory text and the impacted document section. After the solution runs on the updates, the SMEs do not face a pile of raw updates; instead, they receive a structured file (e.g., an Excel spreadsheet) with:
- Events flagged as irrelevant, with clear reasoning
- Events flagged as relevant, mapped to affected processes
- Draft process changes for each affected process
The SME then reviews and adjusts where needed – keeping the human in control while increasing productivity and output.
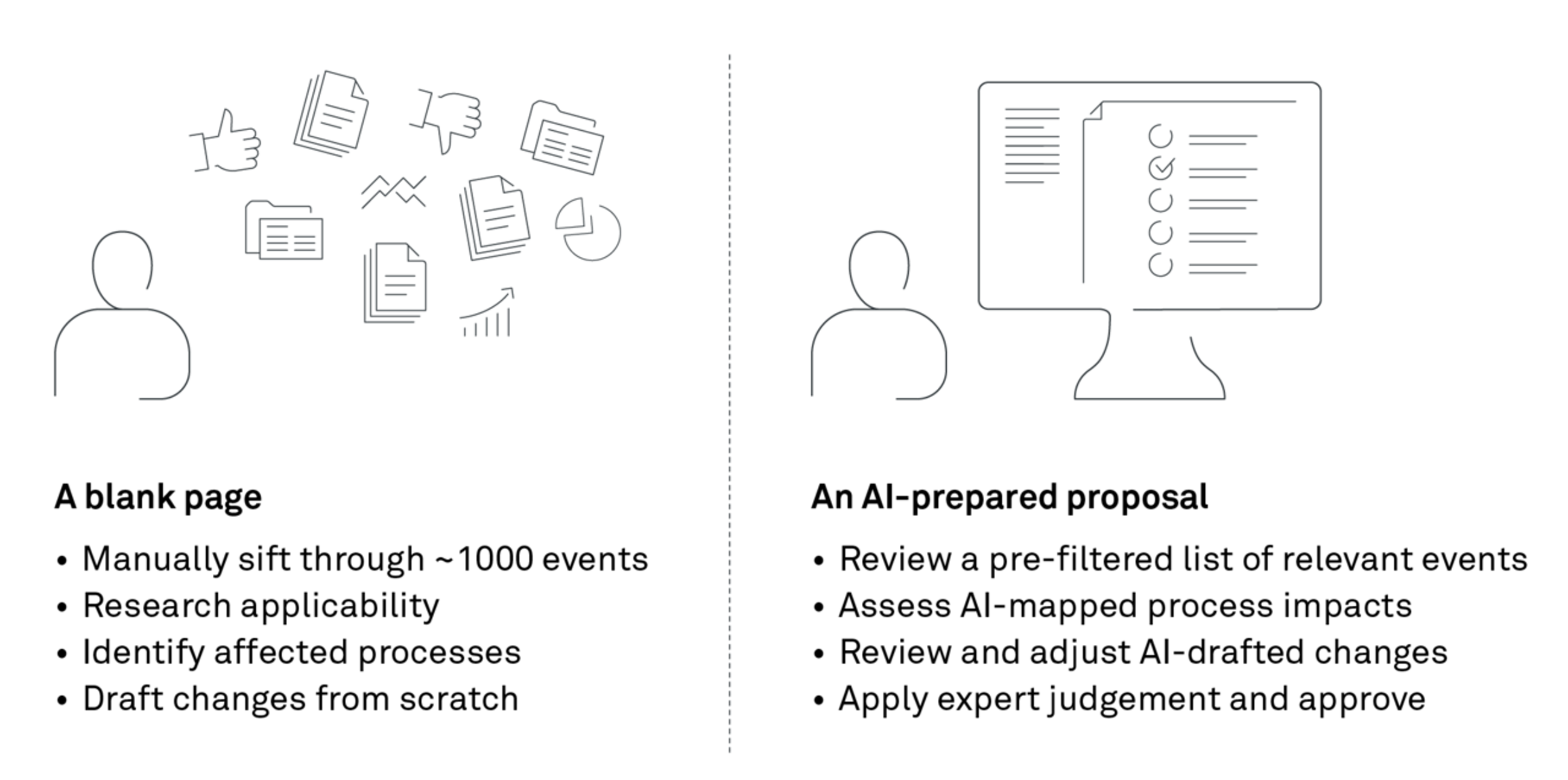
The work does not disappear, just as the people are not replaced, but the process has changed drastically. This emphasises the importance of rethinking the structure of a process when considering the utilisation of digital technology. The technology should play a predefined role, not simply be used to fix an issue and then be placed on top.
The impact
The impact of implementing the triage functionality was obvious:
- Out of 1,500+ historical data points, 42% of regulatory events were filtered as irrelevant with 100% recall
- Zero false negatives observed in testing
- Full auditable reasoning
- Human baseline and productivity gains – do more with the same
As mentioned in the introduction, this project clearly questioned the statement, “Can we fully trust the AI?” In general, for stochastic models in a GMP context, probably no. But can we create a context and a structure around the technology which minimises or even eliminates error with human supervision. Yes, we can.
What happens then? An interesting consequence of the productivity gains in the project was that the classical conversation shifted. The client was not looking to reduce staff. Instead, they wanted to understand how to scale their business further, utilising the saved time to improve operations, or, put simply, doing more with the same.
Related0 4


Article
Read more

CFO Advisory #2: Lead finance through the uncomfortable middle
Set the direction. Design the approach. Protect the capacity to learn.Article
Read more
