Article
– a structured approach to deriving the business value of being data-driven

Article
Read more
15 June 2022
For many companies, data in some shape or form has been at the top of the agenda the last decade. Despite the large amount of attention on the data domain, many companies are yet to see the full range of expected benefits. One of the reasons for the missing impact is the lack of sufficient budget allocation to reach a fully professional data ecosystem.
Many senior executives face the same question: what is the value of our data ecosystem, and why do we even bother investing?
So how do we clearly communicate the value of data to the rest of the organisation, and how do we do that in a way everyone is familiar with?
In this article, we introduce a structured approach to the valuation of data. We have found inspiration in the private equity world where the ability to make good valuations of a range of assets is a core competency.
As you might have read in the previous article “A use case-driven approach to AI adoption”, we are keen to use data use cases throughout our work with data.
The emphasis on business value and being able to prioritise accordingly should steer our every move, and a simple method for achieving this is exactly what we will present in this article.
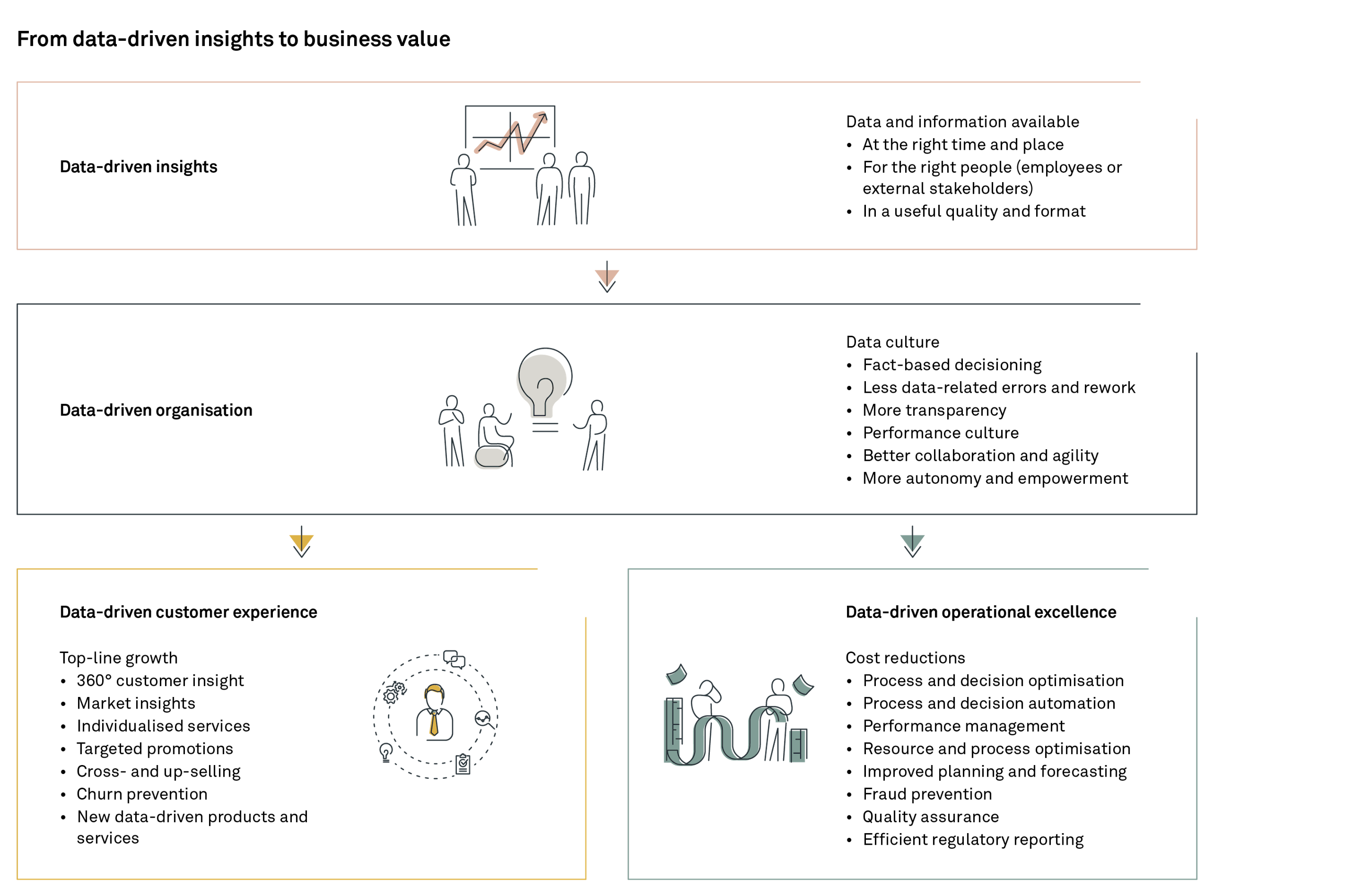
One of the reasons that many companies find it difficult to associate a specific value with investments in data infrastructure is the different levels on which being data-driven can increase efficiency of the organisation.
More specifically, we can derive value by looking at the relations between the raw insights (which may not create value in or of itself), through establishing a new mindset/culture and ultimately arriving at the business value creation – either top-line growth or cost reductions. Acknowledging that there are different types of value, and – more importantly – that insights do not necessarily generate value is the initial step towards our suggested route (see figure 1).
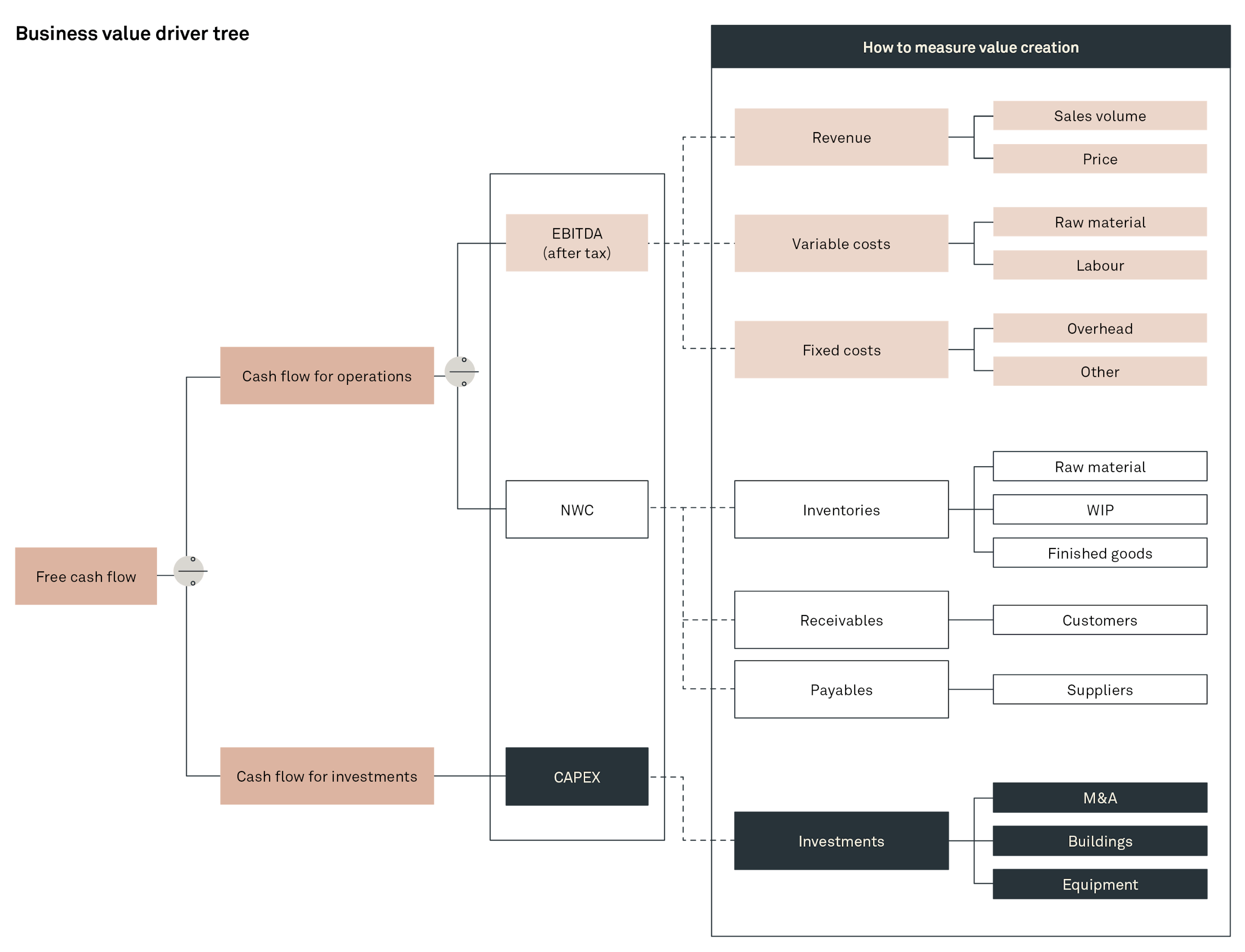
To help establish our approach to valuating data, we found inspiration in the world of private equity. Private equity fund managers are daily tasked with the valuation of assets. If this model can be used for the valuation of factories, service organisations, ships and planes, our logic is that it can just as well be used for valuation of a data ecosystem.
When fund managers in a private equity firm are to estimate the value of a specific asset, they look at how this asset impacts the value drivers of the company in general. Typically, they use a variant of the business value driver tree (see Figure 2). Whilst the overall structure is fixed (in most instances), the details as to what creates the actual value will vary.
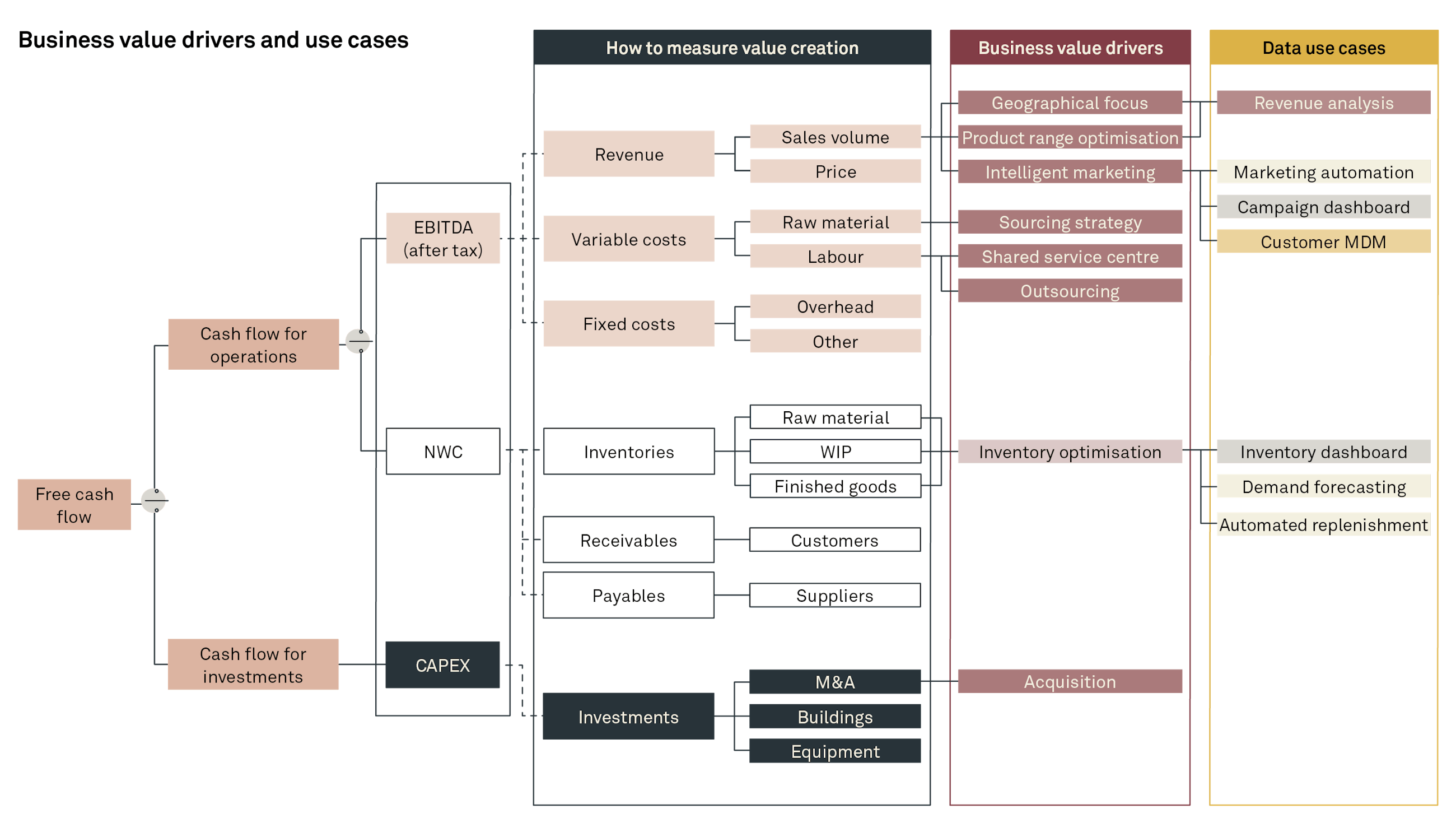
Having established the business value driver tree to describe the fundamental value creators, we proceed to unfold each item into a series of value drivers and in turn the underlying data use cases.
The data use cases on the far-right side are effectively what becomes the scope of our technical implementation. In many cases, a project will start with the right side and lose track of why they were doing them in the first case. Thus, by starting from the fundamentals and using the tree analogy, we understand exactly why we are pursuing which use cases. It furthermore allows us to monitor and measure how successful (and with it a series of informed learnings) our initial hypotheses were.
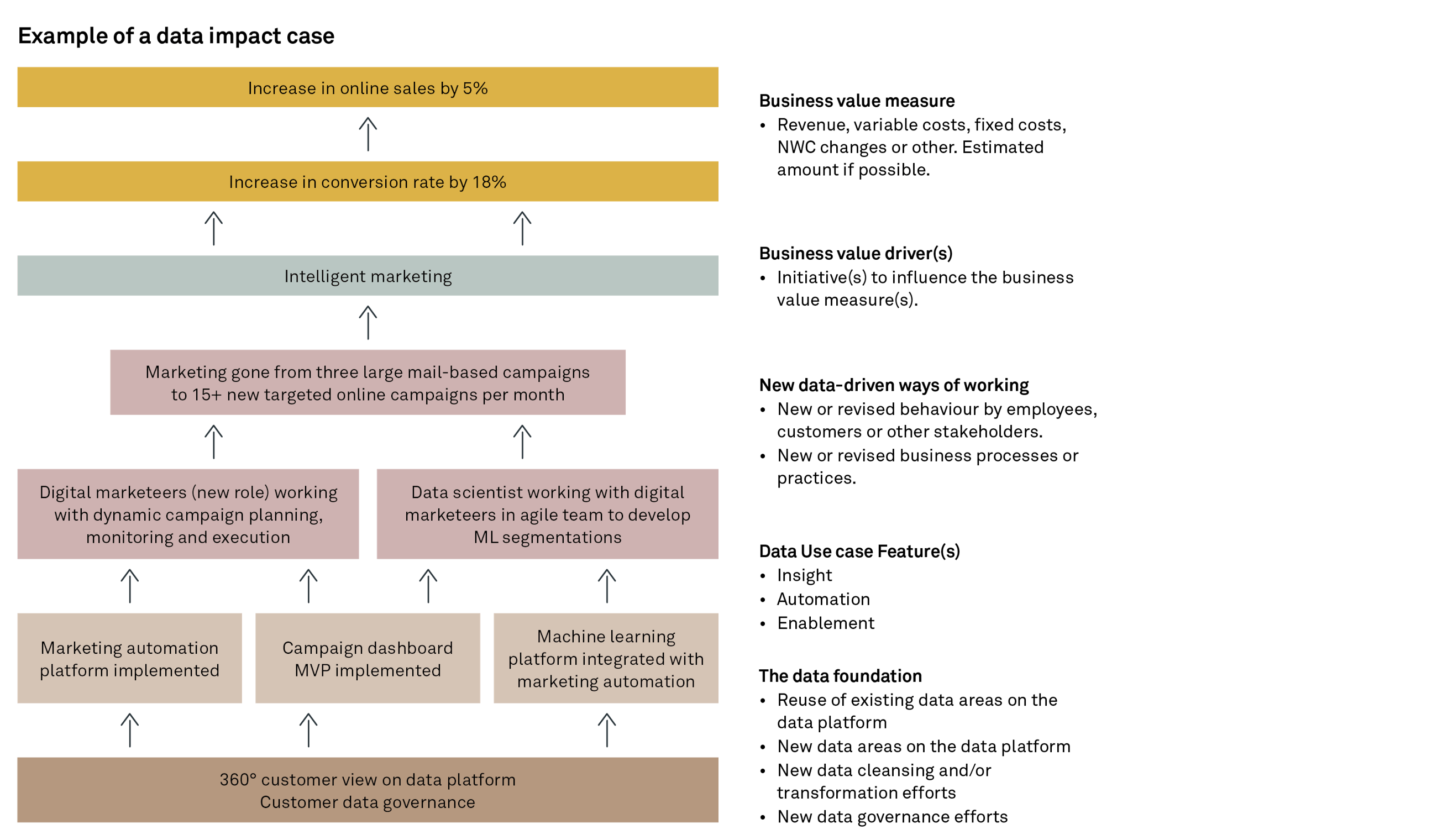
For example, if we wish to increase our revenue, this is driven by our sales volume and our prices. The business value drivers related to the sales volume might be a geographical focus, product range optimisation or intelligent marketing. Only now are we able to connect our data use case of “marketing automation” directly to our business value driver of “intelligent marketing”, thus creating a clear link back to the core strategy of increasing sales volume.
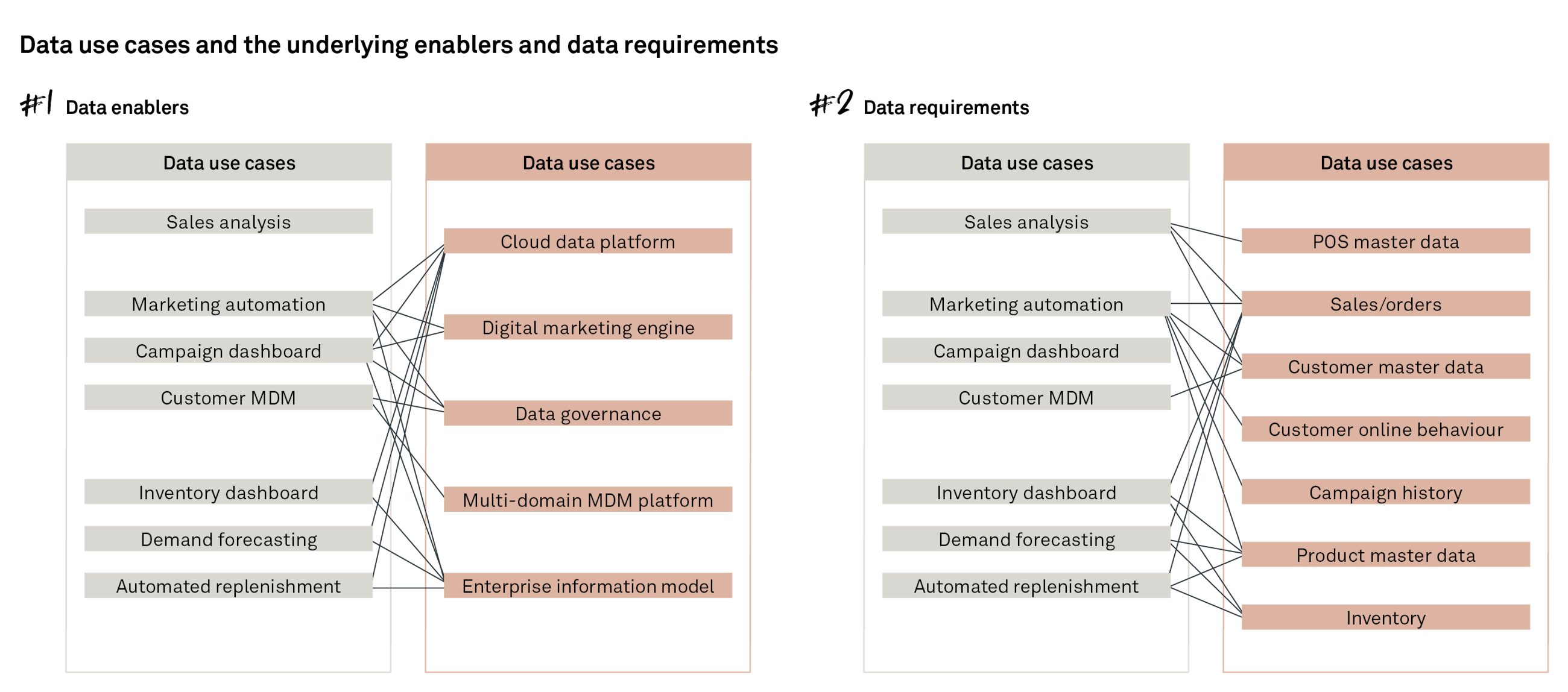
As described in our previous article “A use case-driven approach to AI adoption”, you should always start by establishing the business value. However, to perform any reasonable prioritisation, you would also need to assess the feasibility. To perform a simple feasibility (and high-level estimation) study, we would enrich the most valuable data use cases with the required enablers and the necessary data requirements. Together, these should form most of the required information needed for an initial judgement. Particularly the data requirements (and quality) are often what will make or break the project in the end, however, they are often neglected early on.
Mapping the data requirements and enablers directly to the use cases and thus to the business value drivers also allows us to visualise the derived benefits of a given foundation. It could be that by investing in a cloud data platform for marketing automation we are also unlocking the potential to create demand forecasting at the same time.
Typically, the enablers are hard to sell to the executives funding the project – yet by clearly mapping them to use cases (and in turn all the way to top- and bottom-line growth drivers), we will be able to argue our case much more effectively.
With a structure in place that maps business value (and underlying business fundamentals) to data use cases, we typically want to communicate our results in an easy-to-read form. We propose a data impact case that clearly communicates why and to which extent we are carrying out our efforts. We can even break it down further and set up our dashboards (and reporting) to monitor whether we are on target or not.
Basically, this simple one-pager becomes an instrument for describing our efforts early on. But even more so, we get a standardised means of analysing past projects so we can make even better investments in the future. Furthermore, it describes the cultural and people aspects (see the “Ways of working” section in Figure 4) of the project. This is often forgotten in our communication, yet success of any initiative is largely driven by a need to change people’s behaviour, and the same goes for data projects.
The data impact case is an adapted version of the impact case. The impact case lies at the heart of our Half Double initiative, which we use for all projects at Implement.
The method we propose in this article provides you with a visual and tangible tool to frame where to begin your efforts and define what good looks like. The method furthermore provides for a structured means of estimation and project breakdown with emphasis on understanding how the value is released.
Establishing the actual value of data is not trivial; however, by knowing how and where it is needed (and for which value drivers), you gain an unprecedented understanding of its value.
Ultimately, the method gives decision makers the means to invest in the right things at the right time.
In this article, we have presented our preferred means of deriving the business value of data use cases and prioritising accordingly. However, several alternatives exist, and – depending on your scope – there might be other more suitable methods available. One such method might be the use of the customer (or consumer) journey and mapping each step to use cases. In some cases, a combination might also be the preferred option.
Learn more about these alternatives here.



