Article

Article
Read more
2 February 2022
Artificial intelligence has the potential of changing both businesses and lives. We are already surrounded by AI systems (the output of data science) whether it is when we get product recommendations during online shopping or when our navigation can guess our destination before we have entered a single character in the search field.
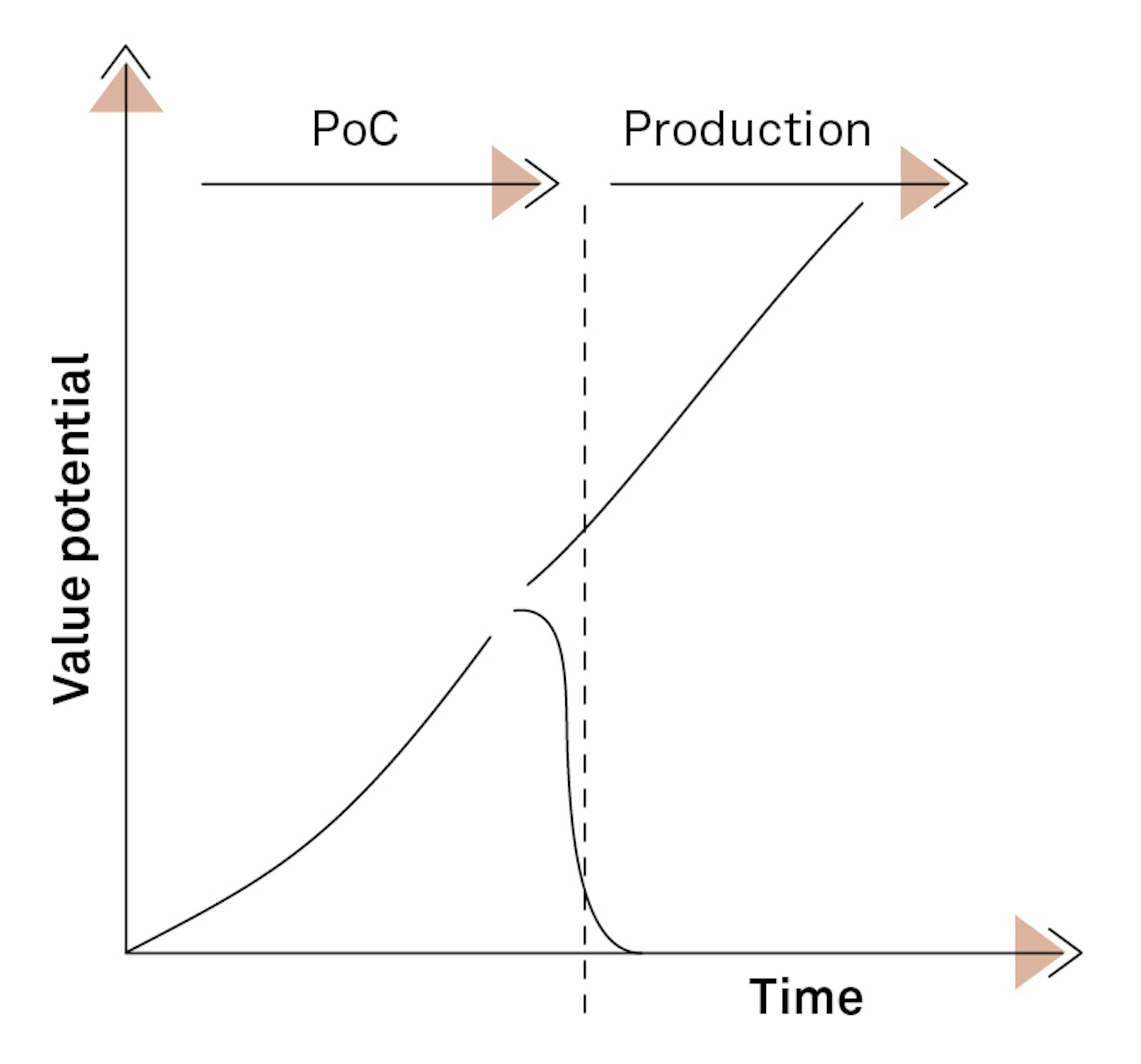
AI, machine learning and many other synonyms have been subject to hype for almost a decade now, and at Implement Consulting Group, we are seeing companies now moving into the next phase of their AI and machine learning adoptions. The first movers and early adopters already have AI systems as an integrated part of their business processes. However, most companies are struggling to take the difficult leap from proof of concept to having reliable AI algorithms as part of their production IT systems. For many companies, this is a true make-or-break situation – particularly considering how the ability to learn from and adapt to data will most definitely be a key competitive parameter across most – it not all – industries in the next decade.
Many corporate strategies contain one or several points such as “being data-driven”, “utilising data as a strategic asset” or “leverage the potential of artificial intelligence”. For the technical parts of the organisation, it might be tempting to rush off and purchase a cool platform for doing data science and thereby fulfilling the corporate strategy. The hypothesis might be that the value will naturally appear along the way when the right technology is in place. Problem is, if technology is the only focus, the value most often is never realised.
Successfully implementing AI systems in general is extremely complex both from a technical and organisational perspective. The right technology must be chosen from a large technology landscape, and it is necessary to locate the right balance between technology and business domains. When the tech stack has been decided, the operating models will have to be designed and implemented. At the same time, the organisation might need to be adjusted, and the mindset of the organisation must be changed to think and work in new ways.
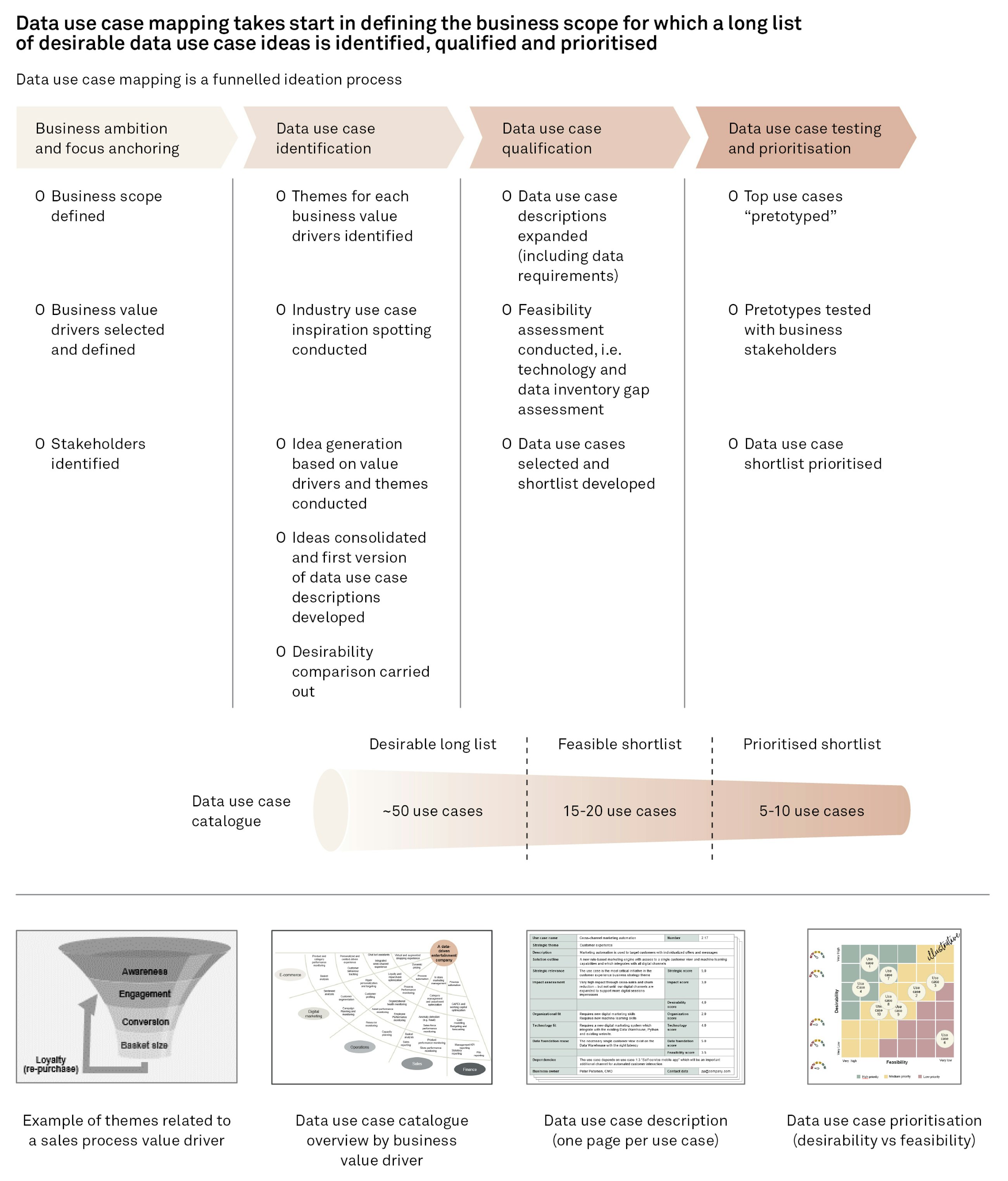
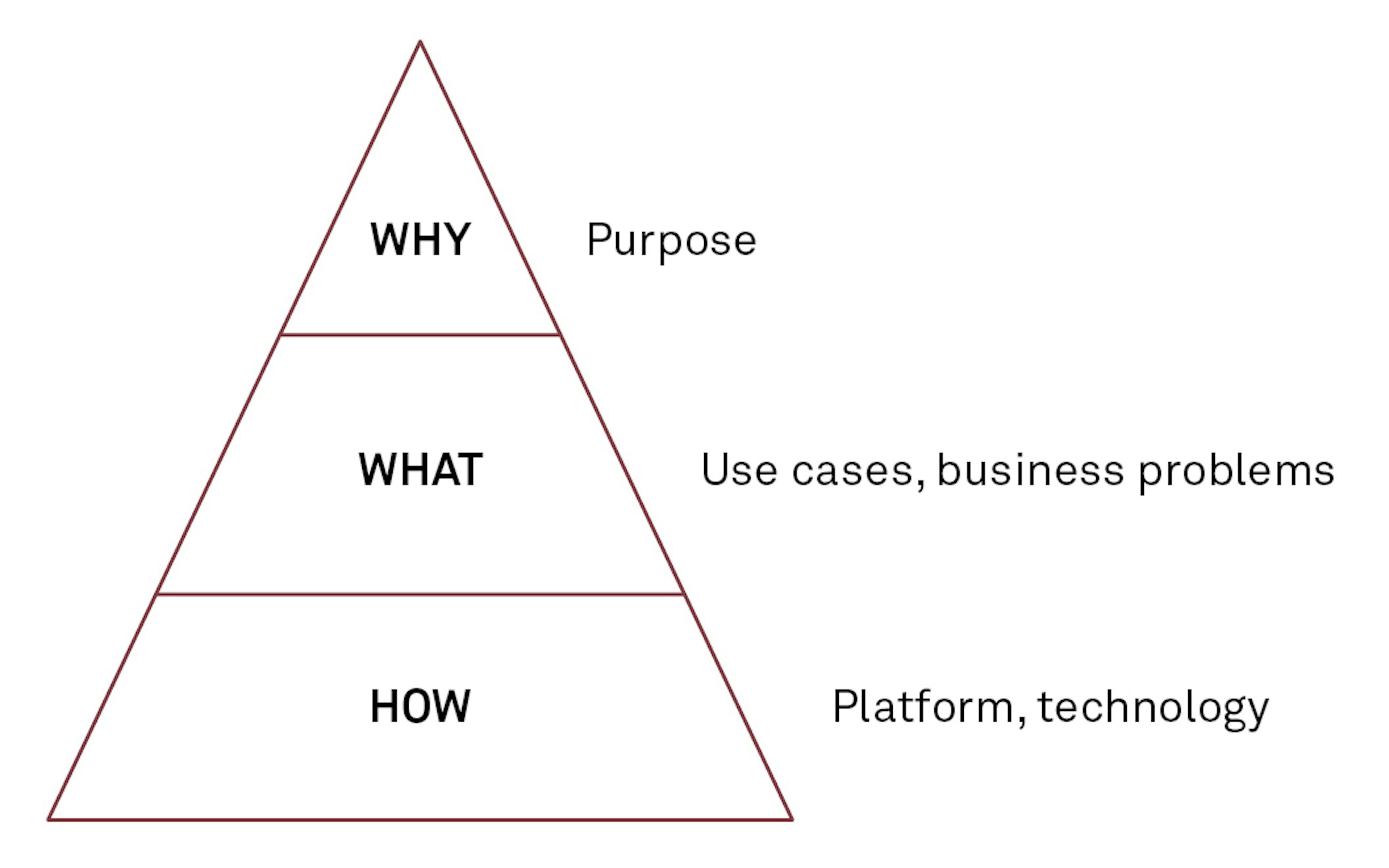
To ensure that the expected value is realised from data science investments, we believe that data science implementations must be started backwards by asking the simple question of Why we want to have a data science capability in the organisation in the first place. What are the use cases that justify making this investment (typically assessed by effort vs impact comparisons – see below), and is it realistic to get an acceptable return on the investments made if those use cases are implemented?
Starting from specifying business-driven use cases has three good reasons:
Delivering impact as fast as possible is a key success factor in any organisation that embarks on a data science implementation journey. We are asking senior stakeholders to invest in unknown technology that they might not fully believe in or fully understand. We are asking employees to change existing habits and ways of working. To ensure momentum, we need to quickly demonstrate the potential of working in new ways and investing in new technologies.
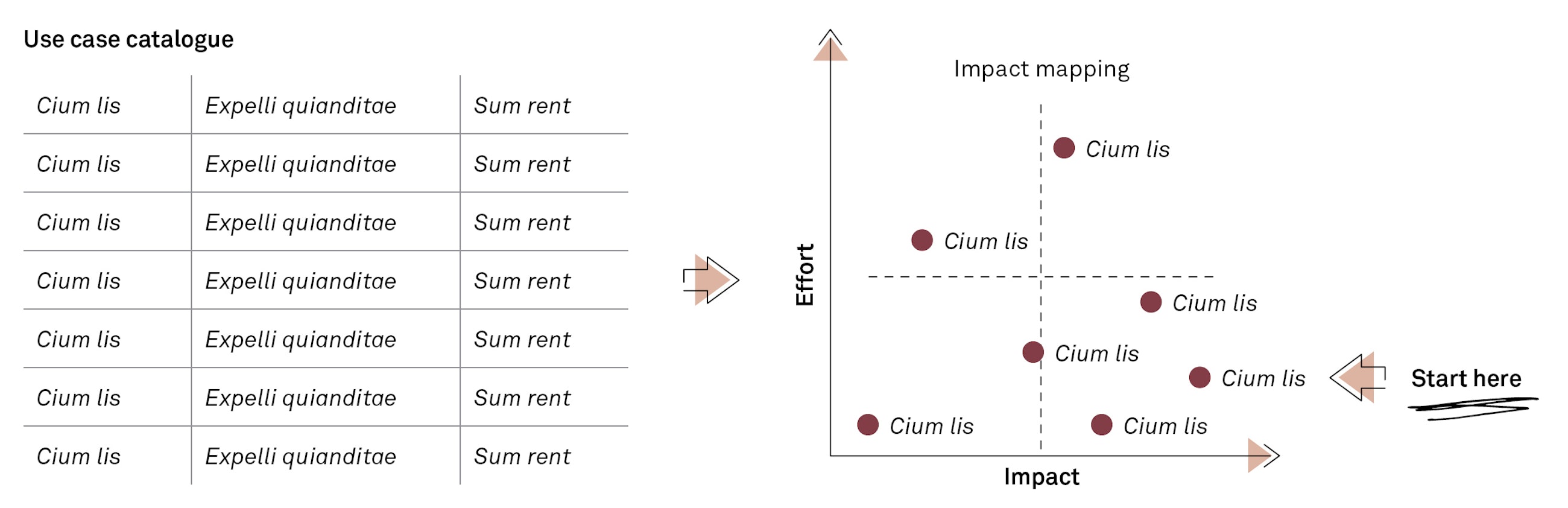
It is in the core of agile development methods to deliver minimum viable products. Adopting that line of thinking into our data science implementations is one of our suggested cornerstones. By establishing a use case catalogue, we can choose to go for high-impact, lowest effort use cases first. When having selected the easier use cases to get value from, they should be implemented incrementally in the simplest possible form first to prove their value as soon as possible. Typically, we go through a funnelled process in which we gradually get to the desired shortlist as depicted below.
The current technology landscape within the data and analytics field is extremely diverse. At one end of the spectre, you will find open-source tool stacks that offer full flexibility and modularity – this comes at the price of high implementation and operational costs. At the other end of the spectre, you will find specialised tools able to handle the entire value chain from data integration to analysis and even pre-built models for specific purposes.
For many companies, the complexity of the technology landscape means that choosing the right combination of tools (tech stack) can be very challenging. In some cases, this results in slow decision processes and delays in the data science projects or even worse: it leads to no-decision scenarios where the project loses traction before it even gets started.
What we propose is to have a clear picture of the target architecture of the platform early but to build it gradually. By having a focus on solving real business problems in the simplest way possible instead of focusing on the technology platform, it is possible to proceed with minimum viable setups that solve the actual business problem with the minimum technology footprint.
For this approach to work, it is necessary to have a clear picture of the target architecture for the data science tech stack. This does not mean that all parts of the architecture need to be implemented from the onset, but it ensures that components used for early implementation fit into the end vision for the data science ecosystem. Therefore, we suggest deriving the “leanest” target architecture in parallel with assessing use cases – yet it can only conclude once you know exactly which use cases derive the most value and then build it incrementally.
By taking an iterative approach and by placing the focus on business value instead of technology, it is ensured that the platform complexity gradually increases as the project matures and that it follows the return of invested capital.
Asking for funding or for people to spend several months of their lives to deliver an enabling technology is quite a lot easier if you can tell them Why they are doing so. For that Why to be meaningful and authentic, it needs to be reflected in tangible use cases that deliver on the Why. By starting AI implementation projects with a focus on business-driven use cases and a clear purpose, the tasks of finding the right technology platform, enabling technologies and operating models become much easier.
Having a value pool of use cases that deliver a clear Why will make it easier to get the rest of the organisation on board as well. You will be able to clearly explain to the operational side of the business why they are spending time getting data for you and changing their working habits to be more data-driven.
By starting our data science implementations with identifying the value pool of use cases and making strategic choices on which use cases to deliver first, we ensure three things:
In this article, we have touched upon how and why it is critical to start data AI implementation projects backwards by asking what the business goals are and afterwards identifying what capabilities are necessary to deliver on those ambitions. Having the use cases in mind from the outset of AI implementation projects ensures that business value is maximised from the very beginning while at the same time contributing to sustaining long-term business value.



