Article
The ins and outs of MLOps

Published
14 December 2022
For many organisations, artificial intelligence (AI), and so machine learning (ML), is becoming an increasingly important part of their strategic road maps. The organisations have realised the added value that advanced analytics solutions can bring to their company and have perhaps already hired the first data scientists to lever the possibilities of AI.
However, if we want to ensure that we are developing machine learning use cases that are not just becoming another proof-of-concept (PoC) in the dreaded PoC graveyard, we need to consider how to deploy the machine learning models after they have been developed.
When deploying machine learning models into production, it is crucial that we take a structured approach. We need to ensure that the models are always representing the world they are trying to simulate, and that the output is unbiased and relevant. As the world is changing, so will an ML model also need to change as models become stale and outdated if no measures are taken to avoid it.
Unlike in classic software development, a bug in the ML model might not result in an immediate failure to run but could perhaps just make the model underperform or even give wrong outputs. To detect a case like this, it is important to have adequate monitoring in place.
The process of continuously ensuring high-quality data, up-to-date trained models and the deployment of models is commonly referred to as machine learning operations or, in short, MLOps. With this article, we hope to shed some light on the key concepts behind MLOps and hopefully convince you that by only using a structured approach to the deployment of machine learning models you will be able to continuously reap the added value that ML models bring to your organisation.
The machine learning project lifecycle
“All of AI, (..,) has a proof-of-concept-to-production gap. The full cycle of a machine learning project is not just modelling. It is finding the right data, deploying it, monitoring it, feeding data back [into the model], showing safety – doing all the things that need to be done [for a model] to be deployed. [That goes] beyond doing well on the test set, which fortunately or unfortunately is what we in machine learning are great at.”
- Andrew Yan-Tak Ng
Andrew Yan-Tak Ng is the founder of deeplearning.ai and co-founder of Coursera and Google Brain team. As he states above, the true project lifecycle of an ML project goes way beyond the initial modelling and performance estimates on a test set. The nature of how machine learning models work makes the machine learning project lifecycle highly iterative.
After scoping a machine learning project, the first step is data preparation to create a data foundation on which a model can be trained. However, after the initial training of a model, the data preparation step might need to be revisited for additional performance increase. Likewise, when the machine learning model has been trained and deployed, monitoring the output might reveal that you should re-train the model, or that the data should be updated.
The MLOps approach seeks to encapsulate this iterative nature of the project as illustrated below:
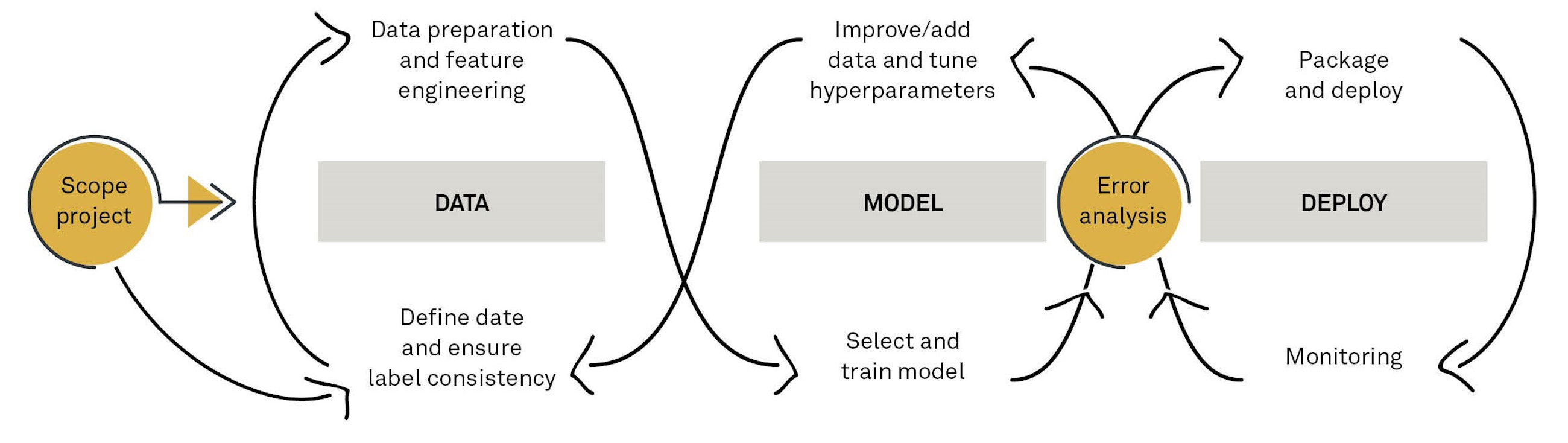
Different parts of the machine learning project lifecycle requires different competencies:
- Data might be required by a data scientist in many cases but really calls for a dedicated data engineer with knowledge of both the tools, like server query language, and methodologies, like data modelling, in addition to some business- specific knowledge of the sources of the data.
- Model will most commonly be handled by data scientists, developing well- performing models using modern architecture and ensuring that the predictions are as valid and accurate as possible.
- Deploy is often also performed by data scientists but really calls for an ML engineer with extensive knowledge of matters like automatic deployment, version control, model monitoring and extended versions of frameworks, whereas the data scientist might be more familiar with the core components.
Many individuals can switch between these different roles in day-to-day operations, but it is important to understand and respect the individual roles, even if they are filled by the same person in practice.
But as stated by Andrew Yan-Tak Ng, there is most often a gap from performing well on a test dataset to the point where proper value-adding machine learning is deployed in production.
Let’s therefore try to dive a bit deeper into the different stages of the MLOps model, highlighting some of the main issues along the way. We will start where most ML projects start; with the data.
What is data?
Data is information representing facts about our world. It can be as simple as the number in your bank account, a label containing your name or as complex as a 44,100 Hz audio file or volumetric video.
At the highest level of generalisation, we would typically divide data into two categories; unstructured and structured data.
Unstructured data refers to data that do not follow a conventional data model. Among other things, this includes speech, text, images and video.
One common denominator for unstructured data is that humans are very good at extracting information from it. Most adults will be able to read a text and report key takeaways or look at an image and describe what objects are present. This makes unstructured data easy for humans to label and create a dataset applicable for supervised machine learning models.
Unstructured data is usually rich and complex. It is hard to work with because tools like Excel handles it very poorly, but digging into it can be very rewarding.
Structured data is the tabular data we know from, for example, lists of transactions or customer master data.
Structured data is harder for humans to label, as not many people would be able to look at a large spreadsheet of data and mark anomalies. In these cases, we usually rely on historic events to provide labels.
Structured data is usually simple, but accurate. It is easier to work with and is often more reliable than unstructured data.
How much data do I need?
To succeed with machine learning, it is not strictly necessary to have big data available. Sometimes, we can succeed with 50, 100 or 1,000 samples. However, we can only identify simpler patterns from smaller datasets, so be aware of the limitations imposed by your data volumes.
If we are working with small datasets, the quality of the data is everything, and making sure that labels are correct becomes increasingly important. But working with large datasets does not mean that you are completely out of the woods – large datasets can have small data problems too. Imagine, for example, an unbalanced dataset with few samples in one of the classes to predict. If this subset of samples has low quality of data, it will be very difficult to train a model to predict this class correctly.
Data-centric AI
In the machine learning community, there has been a shift towards being increasingly aware of the effect that the quality of the data will have on the model output instead of focusing on the tuning of the model to get good performance. The preparation of data should therefore be an integrated part of the deployment of a machine learning model.
While the project is still in the PoC phase, it is alright to make the data preprocessing a manual task, but as soon as the model gets deployed, we need to make sure that the data preparation is replicable. Having a good overview of the data pipeline includes being aware of one’s data provenance, meaning where did data come from, and data lineage, meaning which steps have we taken in the data pipeline for it to result in the model-ready dataset.
Then, when the data is ready, we can move on to the next step; modelling.
Modelling
Getting to modelling fast can actually be a good idea. This allows the most obvious data flaws to be surfaced early and identify the weak spots in the data pipeline. Just don’t forget to go back and tweak the data pipeline and, in turn, the model again.
To be able to assess the performance of a model, you need to have a baseline to compare with. You can obtain this baseline in different ways, and it will be dependent on the data available and the problem at hand.
The first and simplest way to set up a baseline is developing a simple model to compare against. This might be a simple rule-based or linear regression. If a big fancy model with many parameters and a good training set is not able to significantly improve the performance of a simple implementation, it will most likely not make sense to spend a lot of time and resources to deploy the model to production.
A second step in establishing a baseline could be to establish the Human Level Performance (HPC). This is especially useful in a case where the ML model to be deployed is replacing a previously manual task. As the name suggests, the HPC is a measure of how well a human would be able to perform a task, and the assessment of the model is thus how it compares to the processes in place.
You can also establish a baseline by doing a simple literature search on state of the art within the domain your model is working. This gives an immediate sense of what is even possible to achieve.
And finally, if the machine learning model going to production is a replacement for an earlier deployed model, you might as well use the performance of the earlier system as the baseline to compare performance with.
Compared to the chosen baseline, you might be able to create a model that performs well. However, it can be deceiving if you strictly look at performance on a test set compared to a baseline. You should also investigate how the model performs on key slices of data. This could be performance according to gender, ethnical bias etc. This step is one of the most important steps in the deployment to ensure that we are not introducing biased ML to production.
You should also be aware that for highly unbalanced datasets, you might obtain a high accuracy just by guessing on the majority class every time – and never spotting the rare event classes that you are usually more interested in.
Once you have trained a model, and you are satisfied with the performance, you can move on to the next part of the machine learning lifecycle; deployment.
Deployment
Before deploying the model, it is useful to consider some software-related requirements to the model. These could, for example, include the following:
- Should the model be able to run in real time, or can we run it as batch prediction?
- Can we run the model on cloud, or does it need to be on an edge device or on-premise system?
- What are the compute resources necessary to run the model?
- Is there a requirement for maximum latency on the response from the model?
- What is needed in terms of logging?
- What should be the security and privacy settings for the model in production?
These considerations should be made before the model is ready and trained. They should be part of the design criteria on the chosen algorithm and architecture. Packing the model for deployment will require revisiting these considerations and ensuring that the needs are met.
When the model is packaged and ready to be deployed, there are a few different ways you can deploy the model. You can choose to start off with a shadow deployment in which the model runs in parallel with the existing process and the output is not immediately used for anything. This would often be a useful approach in a case where the model is replacing a previously manual task and the validity of the model needs to be verified. Once the model has shadowed the manual task for a given period and the accuracy of the proposed output from the model matches the human decision, the model can move out of the shadow and become the go-to decision-maker in production.
Another approach to deployment is a canary deployment. In this case, the model is only deployed to a small fraction of the process on which performance measures can then be tested. Once it is verified that the model works for the small fraction, you can ramp up and gradually move the entire process to be automated by the ML model.
And finally, you can choose to do a blue/green deployment. In this case, you have two environments able to perform the same task; one is the old system (blue) and the other is the new system or ML model (green). This offers the possibility to roll back to the old system in case some parts of the processes fail in the newly deployed ML model. The blue/green deployment tactic is especially useful in a case where the ML model to be deployed is replacing a previous model.
It should also be noted that deploying a machine learning model does not necessarily equal full automation of a process. We would often see the degree of automation placed somewhere on the scale below. “AI assistance” is the case where a human is assisted by the model for decision-making, and “partial automation” is when the model needs human evaluation of uncertain predictions. Both can be referred to as “human in the loop”.

Maintenance
The first deployment only takes us halfway to a fully deployed ML model. The other half is maintenance.
To maintain the deployed model, monitoring is key and can be achieved by developing a set of dashboard reporting key KPIs about chosen metrics. These metrics could be:
- Software metrics: how are we doing on memory, latency, throughput?
- Input metrics: has the input data changed? Is the average or deviation of key features stable within some range?
- Output metrics: how often does the model return null? How often is the request re-sent by the end user? How often do we detect different classes? Is the model’s certainties approximately stable over time?
After finding the right metrics to monitor, thresholds should be implemented to alert once a metric is out of the norm.
One of the most important reasons to monitor the deployed models is to ensure that you do not experience data drift or concept drift. Data drift will happen when the input data change and the data presented to the model in production no longer adequately reflect the data on which it was trained. Concept drift is when the relationship between your input data and output data changes. Common examples of this could be a change in weather data caused by a shift in season, or that the customer purchasing behaviour changes over time due to changes in the economy.
Summary
MLOps is a broad discipline encompassing the data-centric AI field to good deployment practice and software traditions. Broadly, it can be broken down into three interdependent phases: data, model and deployment. An ML developer or ML development team will need to move back and forth between these phases throughout the ML model’s lifecycle.
We hope that this article has provided you with some insights into the end-to-end process of ML development and provided some helpful tips to start you on your development journey.
Facts
Machine learning
In 1959, Arthur Samuel defined machine learning as a “field of study that gives computers the ability to learn without being explicitly programmed”. In its essence, machine learning is humans giving instructions to the computer on how to learn in order to complete an objective.
Supervised vs unsupervised learning
Supervised learning utilises models that are designed to infer a relationship between input data x and labelled outcome data y. Supervised learning aims to learn a function f such that the distance between the actual outcome y and the predicted values f(x) is minimised.
Unsupervised learning utilises models that can handle unlabelled data. As data often has structure, the goal of unsupervised learning is to uncover the patterns and structure in data.
Train, validate, test
To make sure that your ML model generalises and performs well after being deployed in production, data are split into three subsets: training data on which the model is fitted, validation data which is used throughout the training process to adjust the parameters of the model and, lastly, the test data which have been withheld from the training process and are used for the final evaluation of the model.
Want to know more?0 3
0
3If you need further assistance, please do not hesitate to reach out:
Related0 4
Article
Read more

Digitaliseringens rygrad
Datacentre i Danmark driver det moderne digitale samfund, bidrager til den grønne omstilling og skaber jobs og økonomisk...Article
Read more

The AI opportunity for eGovernment in Belgium
Adopting AI in public administration to enhance productivity and create value for citizens and businesses.Article
Read more

The AI opportunity for eGovernment in Poland
Adopting AI in public administration to enhance productivity and create value for citizens and businesses.Article
Read more
