Article
- handling text as data

Article
Read more
7 April 2022
The big data revolution has been raging for a few years. And at roughly the same pace as organisations have begun setting up structured data warehouses for reporting purposes, new and exciting data sources such as text and audio are to a higher extent seen as valuable sources of information. These data sources hold a potential for creating value in everything from customer journeys to public services, and they often contain value and insights beyond what traditional tabular formats do. In other words, audio and text data contain a huge potential for generating – and acting on – insights arising through traditional channels that have not traditionally been as accessible as they are right now.
In its entity, this guide is for people who can envision some of the potentials that lie embedded in text or audio data but who need more comprehensive insights into potentials, requirements and/or methods. Covering these topics, we know that it is necessary to address complex concepts and their impact, and we acknowledge that certain topics may be (too) difficult for the uninitiated. Therefore, we have decided to split the guide into two parts:
The first part is aimed at those recognising natural language processing (NLP) as a fast-emerging field but who still wonder what sort of text is relevant, which use cases are possible, where they can find text data and how the field has progressed – but who at the same time do not need to understand how or why computers interpret text as they do.
The second part is aimed at the technical side of NLP. It is for readers who are curious about the technical aspects such as how to move from text to 0s and 1s that are readable by a computer and how to approach the complexity that inherently lies in working with text and speech as data.
At Implement, we are experiencing an increased demand for data science competencies in general, and the analysis of text as data (often labelled as natural language processing or NLP) is a big driver of that.
What is NLP, and how can it be approached?
In this first part of the guide, we will be covering:
First, though, we should agree on when to use NLP – and maybe most importantly, when not to. As with so many other things, we experience a trade-off between approaching a task manually versus deploying advanced analytics.
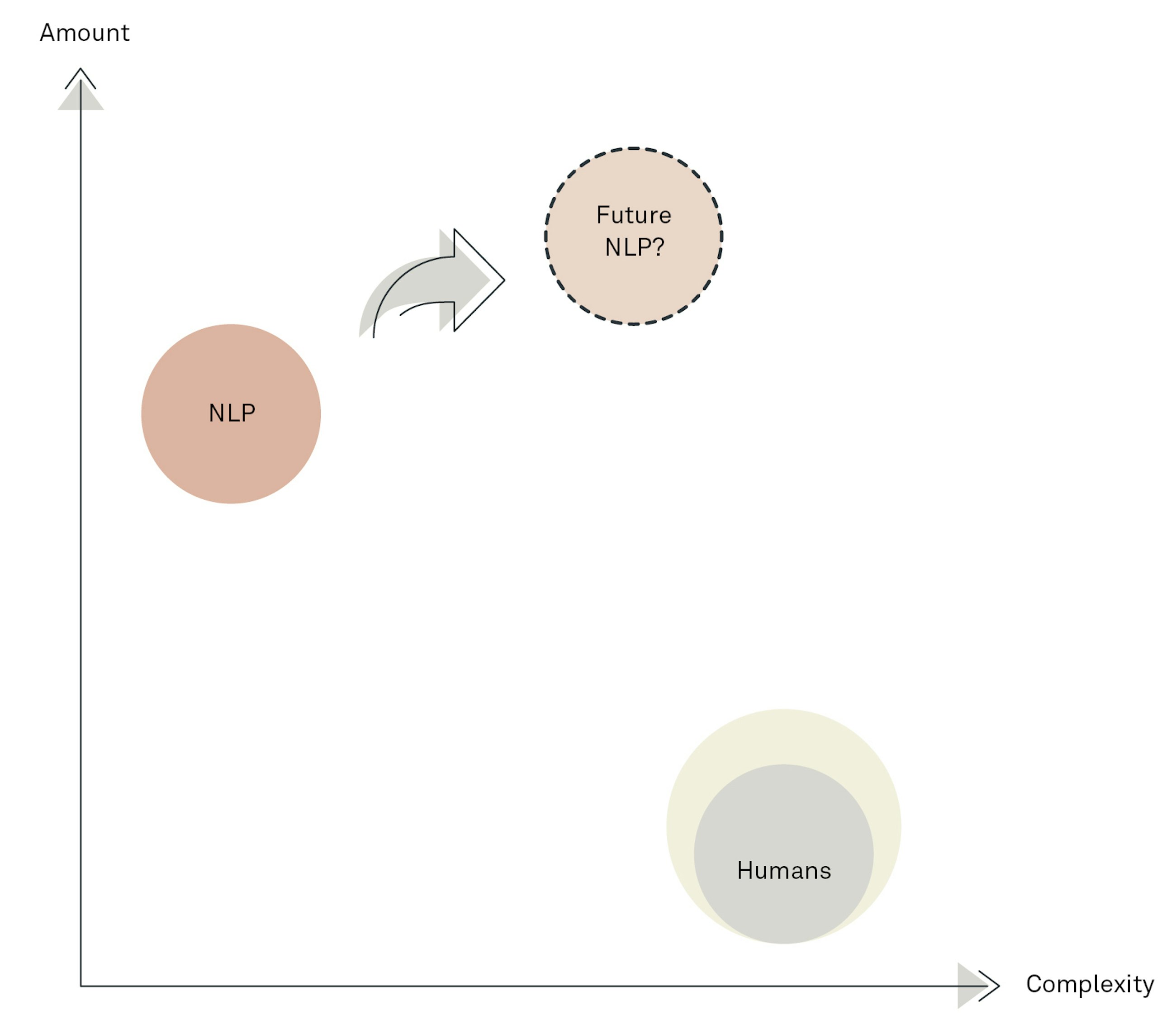
The true value of text analytics lies in the analysis of very large quantities of text, but current NLP solutions cannot grasp the complexities of language to the same degree as a human reader would be able to. Thus, with the use of NLP, we must sacrifice some precision in the analyses, but we are able to conduct our analysis over thousands, or perhaps even millions, of documents. In addition, we see larger and better language models being published at a rapid pace, so perhaps the future of NLP looks like what is depicted in the figure below?
Despite previous warnings, the field has come a long way in recent years. Across our projects, we have already seen natural language processing being used to realise some of the following potentials:
However, NLP is not only becoming more valuable in organisations and professional work. As a matter of fact, you probably encounter NLP several times a day:
Many organisations have large – and steadily increasing – amounts of natural language data that are ready and waiting. Examples include public sector requirements for documentation, e.g. of meetings with citizens, decisions regarding citizens’ rights, hospital logs and much more. In the realm of private organisations, customer contact often occurs via chat(bots), phone calls and/or emails to and from customers.



