Article
En guide til kunstig intelligens og machine learning

Published
28 May 2020
Hvad er data science?
Big data-revolutionen har efterhånden raset i nogle år, og alle virksomheder og offentlige institutioner har mere eller mindre færdige datavarehuse. Men hvorfor? Vi har fået bedre rapportering og bedre indsigt i de daglige operationer. Mere ledelsesrapportering og flere dashboards. Alt det er sådan set værdifuldt, men der kan opnås langt mere værdi.
Data science lover at bringe operationelle løsninger og endnu dybere indsigt til organisationer. Særligt for data science er ønsket om at udvikle løsninger, som kommer med råd i konkrete operationelle situationer, eller fuldt automatisere et skridt i en arbejdsproces. Det er ikke det eneste, det kan, men det er et af de helt store fokuspunkter.
Data science er en disciplin, der samler statistik, dataanalyse og machine learnings fælles metoder i forsøget på at undersøge og analysere virkelige fænomener via data.
Et eksempel kunne fx være en læge. En patient kommer ind af døren, og en data science- løsning præsenterer ikke bare et dashboard baseret på patientens journal, men også et sæt af forudsagte opmærksomhedspunkter for lægen baseret på patientens historik, den nyeste forskning og det nuværende sygdomslandskab i verden.
Patienten får foretaget et scan af sine lunger, som giver besvær, og da scanneren afleverer billedet, foreslår den straks, at en region af billedet undersøges nærmere for potentielle kræftknuder og fremhæver straks området. Maskinen er trænet på millioner af billeder verden over, og lægen er straks mere opmærksom.
Efter patienten er gået, dikterer lægen et notat, som automatisk gemmes som tekst. En algoritme bemærker, at der nævnes et scan af lungerne og tilføjer automatisk en procedure-kode på patientens historik. Det bemærkes desuden, at der er mistanke om kræft, og et opmærksomhedsflag rejses på patienten til fremtiden.
I eksemplet ovenfor blev data science først brugt til at give en bruger overblik ud fra et ellers uoverskueligt informationsgrundlag. Herefter blev der ydet beslutningsstøtte, og et område blev fremhævet. Endelig var der til sidst en fuldautomatisering af journaliseringen af arbejdet.
Vi er næppe helt dér endnu. Men vi er uden tvivl på vej, og i denne guide vil det give indtryk af, hvordan du kan efterprøve og styre data science-eksperimenter i din organisation.
Hvem er denne guide til?
Denne guide er først og fremmest til folk, der vil i gang med at øge data science- kompetencerne i deres organisation. Enten dem selv ved at blive bedre data scientist- eller softwareudviklere eller ved at lede en større eller mindre data science-afdeling. Denne guide giver et dybt indblik i et komplet data science workflow – ikke bare fra data til model, men fra identifikation af det rette problem til opsætning af modellen og til realisering af værdien og vedligeholdelse.
Hvorfor denne guide?
Udfordringen er, at selvom mange organisationer ønsker at begynde med kunstig intelligens, og en del endda forsøger, så møder de systematisk nogle udfordringer, som vi gerne vil forsøge at præsentere en moderne løsning på.
Inspirationen
Vi oplever i Implement en stor efterspørgsel på data science-kompetencer. Det skyldes primært, at mange organisationer sidder inde med store – og hastigt voksende – mængder af data. Det rejser mange steder det naturlige spørgsmål: Kan al den data ikke bringes i spil og skabe forretningsværdi på en eller anden måde?
Det næste, der oftest sker, er, at man finder en medarbejder, som sættes i gang. Enten med at identificere en anvendelse eller blive givet en konkret opgave, som skal løses med en data science-løsning.
Udfordringen er, at en dygtig data scientist har tre kompetencer, der er yderst sjældne sammen:
- En stærk forståelse for softwareudvikling,
- En stærk forståelse for statistik og machine learning,
- En stærk forståelse for den forretning eller det domæne, de arbejder inden for.
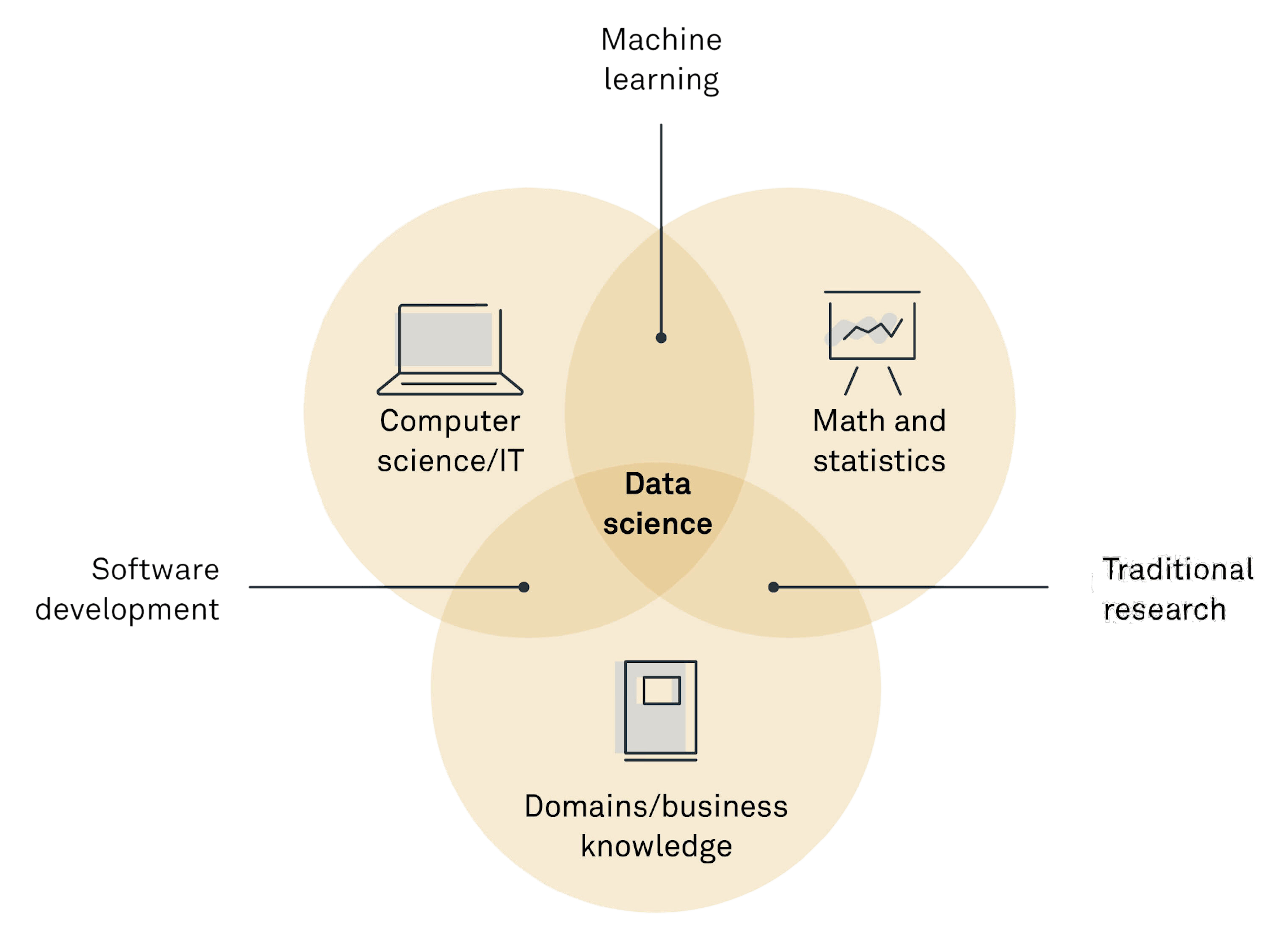
Hvis et af disse elementer mangler, møder data scientisten ofte udfordringer:
- Mangler softwareudviklerkompetencerne, risikerer data scientisten at blive en ekspert, der ikke kan levere løsninger, der rent faktisk bliver implementeret og skaber forandring. Løsningerne forbliver for tekniske eller bliver ofte bare aldrig færdige.
- Mangler statistik- og machine learning-kompetencerne, vil data scientisten ofte have svært ved at levere den tilstrækkelige kvalitet af løsninger, som der efterspørges. De bliver formentlig færdige, og de løser formentlig problemet, men vedkommende er afskåret fra at takle de nye og svære problemer, som de potentielt kunne, hvis de havde en større forståelse for machine learning.
- Mangler forretningsforståelsen, risikerer vedkommende at udvikle flotte løsninger, der ikke finder anvendelse i forretningen, og hvor gevinsterne ved udviklingen aldrig realiseres.
Ikke overraskende er netop udfordringer med at afslutte projekter, opnå den forventede kvalitet og faktisk opleve den ønskede effekt nogle af de mest udbredte problemer i nye data scienceprojekter.
Denne guides indhold
I denne guide vil du blive taget med på rejsen fra den tidligste start med use case- identifikationen og helt til råd om governance af modeller, når de er lagt ud til anvendelse. Guiden består af syv kapitler med følgende overskrifter:
- Kapitel 1. Use case-identifikation: Hvordan sikrer du, at du arbejder på en værdifuld idé?
- Kapitel 2. Dataeksploration: Få overblik over dine data, ikke bare mønstre og indhold, men skabelsen og håndteringen.
- Kapitel 3. Definition af formål: Hvad skal din model optimere for? Hvad er egentlig problemet, vi forsøger at løse? Og hvordan du sikrer, at din model faktisk gør det, du regner med.
- Kapitel 4. Machine learning: Hvad er de statistiske teknikker, vi bruger til at lave vores analyser? Hvordan rammer du den rigtige mængde kompleksitet og sikrer, at din model virker i virkeligheden.
- Kapitel 5. Etik: Data science berører mange menneskelige aspekter fra persondata til automatisering. Kapitel 5 giver en indflyvning i de vigtigste overvejelser og konkrete råd til, hvordan ting beskyttes.
- Kapitel 6. Data science governance: Når modeller skal ud og skabe værdi, skal de styres og vedligeholdes. De skal måske endda opdateres eller i hvert fald overleve, at it-landskabet omkring dem opdateres. Dertil har vi governance.
- Kapitel 7. Governanceværktøjer: Når governance skal implementeres, er der en række hjælpsomme værktøjer. Kapitel 7 giver et indblik i de fem vigtigste fra versionsstyring til modelmonitorering.
Download hele artiklen
Nedenfor kan du downloade hele artiklen:
Data Science
En guide til kunstig intelligens og machine learning
Related0 4


Article
Read more

CFO Advisory #2: Lead finance through the uncomfortable middle
Set the direction. Design the approach. Protect the capacity to learn.Article
Read more
